The debate on how to deploy applications, monoliths or micro services, is in full swing. Part of this discussion relates to how the new paradigm incorporates support for accessing accelerators, e.g. GPUs, FPGAs. That kind of support has been made available to traditional programming models the last couple of decades and its tooling has evolved to be stable and standardized.
On the other hand, what does it mean for a serverless setup to access an accelerator? Should the function invoked to classify an image, for instance, link against the whole acceleration runtime and program the hardware device itself? It seems quite counter-intuitive to create such bloated functions.
Things get more complicated when we consider the low-level layers of the service architecture. How does the system itself get access to the acceleration hardware? Docker allows exposing a GPU device inside a container for some time now, so serverless systems based on top of it can expose GPU devices to running functions. Virtual Machine-based setups rely on the monitor, e.g. QEMU or Firecracker, to expose acceleration devices to the guest.
There are several techniques used to expose a device from the host to a guest VM. Passthrough mode exposes the hardware accelerator as is inside the guest. This mode provides native performance using the accelerator from inside the VM, however it does cause issues with sharing the device across multiple VMs. API remoting, e.g. rCUDA, is another option, where requests are being forwarded to the accelerator device over the network. Finally, there is the option of paravirtual interfaces where the monitor exposes a generic device to the guest, with a very simple API. Applications in the guest send requests to the paravirtual device which are then passed to the hypervisor and dispatched by the latter to an accelerator device on the host.
VirtIO drivers are an example of such paravirtualized frameworks. VirtIO exposes simple front-end device drivers to the guest, rather than emulating complex devices and offloads the complexity of interacting with the hardware to the back-end that lives in the Virtual Machine Monitor (VMM).
virtio-crypto Link to heading
One of the devices described in the VirtIO spec is the virtio-crypto device. The guest chooses the cryptographic operation to perform and passes a pointer to the data that will be manipulated. The actual operation is offloaded through the VMM to the host crypto acceleration device.
A VM is able to use a crypto device by using a combination of cryptodev and virtio-crypto. Requests for encryption / decryption originating from the VM, get forwarded to the backend, get injected to the cryptodev device and end up being handled by the host Linux kernel. Figure 1 presents an overview of the virtio-crypto architecture.
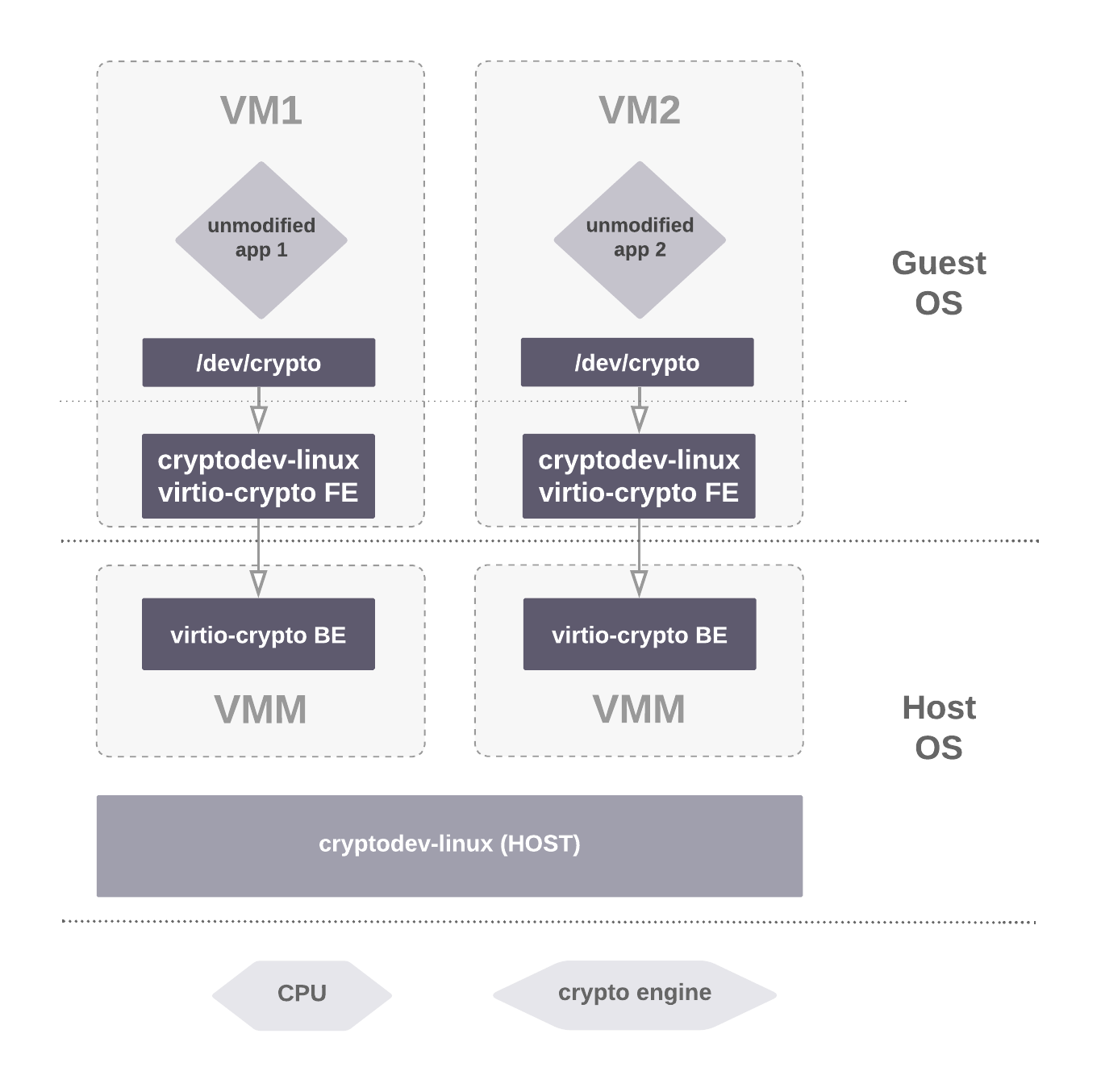
Figure 1: VirtIO-crypto architecture overview
In the context of micro-services (FaaS/Serverless) cryptographic operations are quite common, presented to the user as language/library abstractions. Integrating an off-loading mechanism of these CPU-intensive operations seems like an interesting optimization. To showcase the potential of paravirtual accelerated devices, we implemented a virtio-crypto backend driver for AWS Firecracker. Since virtio-crypto’s frontend is already present in the Linux kernel, all we had to do is implement the corresponding back-end in the Firecracker code base. This effort was relatively straight-forward since Firecracker already provides a number of VirtIO devices, e.g. net and block, which means that all the machinery for communication with the guest was in place.
Figure 2 shows the performance our virtio-crypto driver achieves (light bars) compared to running the computation in the guest kernel using the cryptodev-linux driver (dark bars), when running the AES-CBC cipher. Unfortunately, we have not been able to get our hands on a crypto acceleration device, so virtio-crypto is using the same cryptodev-linux device in the host (the CPU). This means that we do not actually accelerate the operation, but our experiment is quite useful to see the VirtIO overhead of offloading the operation to the host. As expected, the larger the block size of the blob we are encrypting, the better we are able to hide the cost of moving data from the userland of the guest to the kernel of the host.
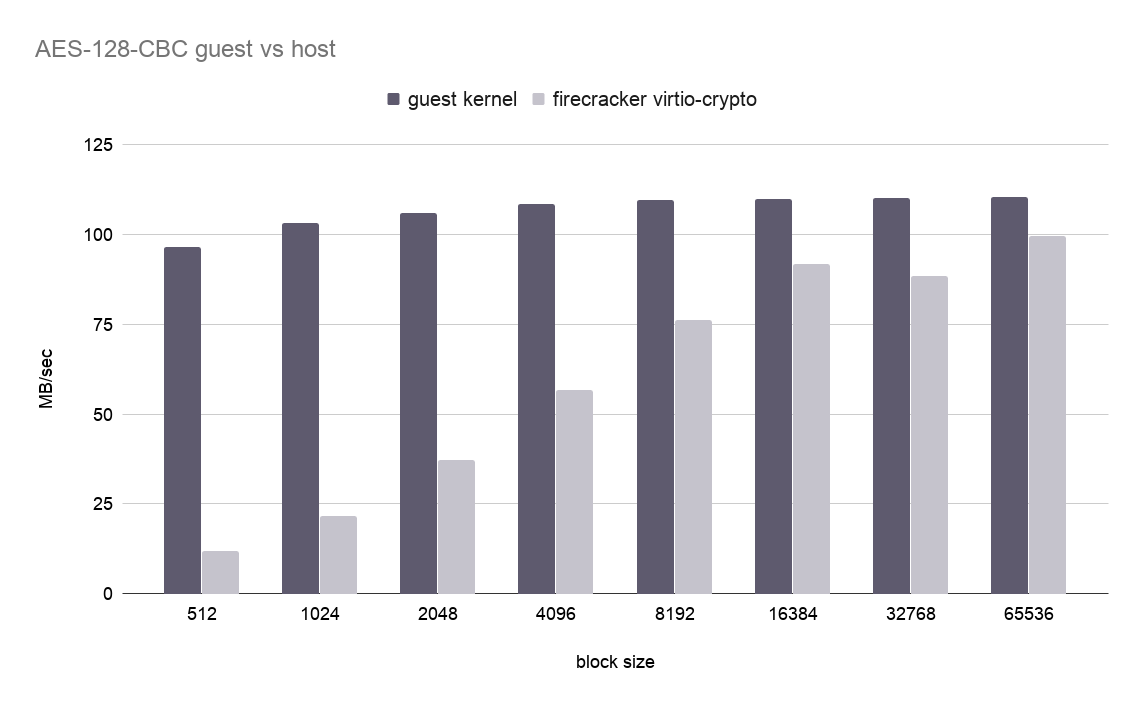
Figure 2: Host and Guest Throughput for AES-CBC-128 vs chunk size
This is encouraging; once there is a hardware accelerator for computation, acceleration capabilities are automatically exposed inside a Firecracker VM in a secure way with reasonably low overhead. Which inevitably leads us to the thought, why only crypto? The virtio-crypto example showcases a simple interface through which we can achieve hardware acceleration, so why not generalize this to other types of acceleration?
This gave us the idea to define a simple, hardware-agnostic API to accelerate any operation, as long as the host supports it. We believe that an API at this granularity is the right abstraction for serverless frameworks, since it moves the complexity of accelerating operations from the guest to the host.
vAccel Link to heading
Let us consider a simple use-case: matrix multiplication. It is a common operation, used in numerous applications, in HPC, Machine Learning, and Big Data. In the generic case, the user running the application on a VM would have to either have access to the GPU hardware and enjoy hardware acceleration, or perform the operation on the CPU, wasting time and CPU cycles.
Instead of passing through the GPU hardware, we choose a different path: we introduce vAccel, a simple paravirtual framework that forwards operation requests to the monitor, which, in turn, uses native calls to an acceleration framework, taking advantage of the hardware capabilities of the host.
The vAccel framework allows workloads that execute on Virtual Machines to offload compute-intensive functions to backends provided by the hypervisor. To achieve this, the system presents a number of host-side accelerator functions to the guest kernel, which are backed by hardware accelerators (FPGAs, GPUs, specialized crypto engines etc.).
vAccel consists of three main parts: the frontend driver, the backend driver and the runtime. An overview of the system architecture is shown in Figure 3.
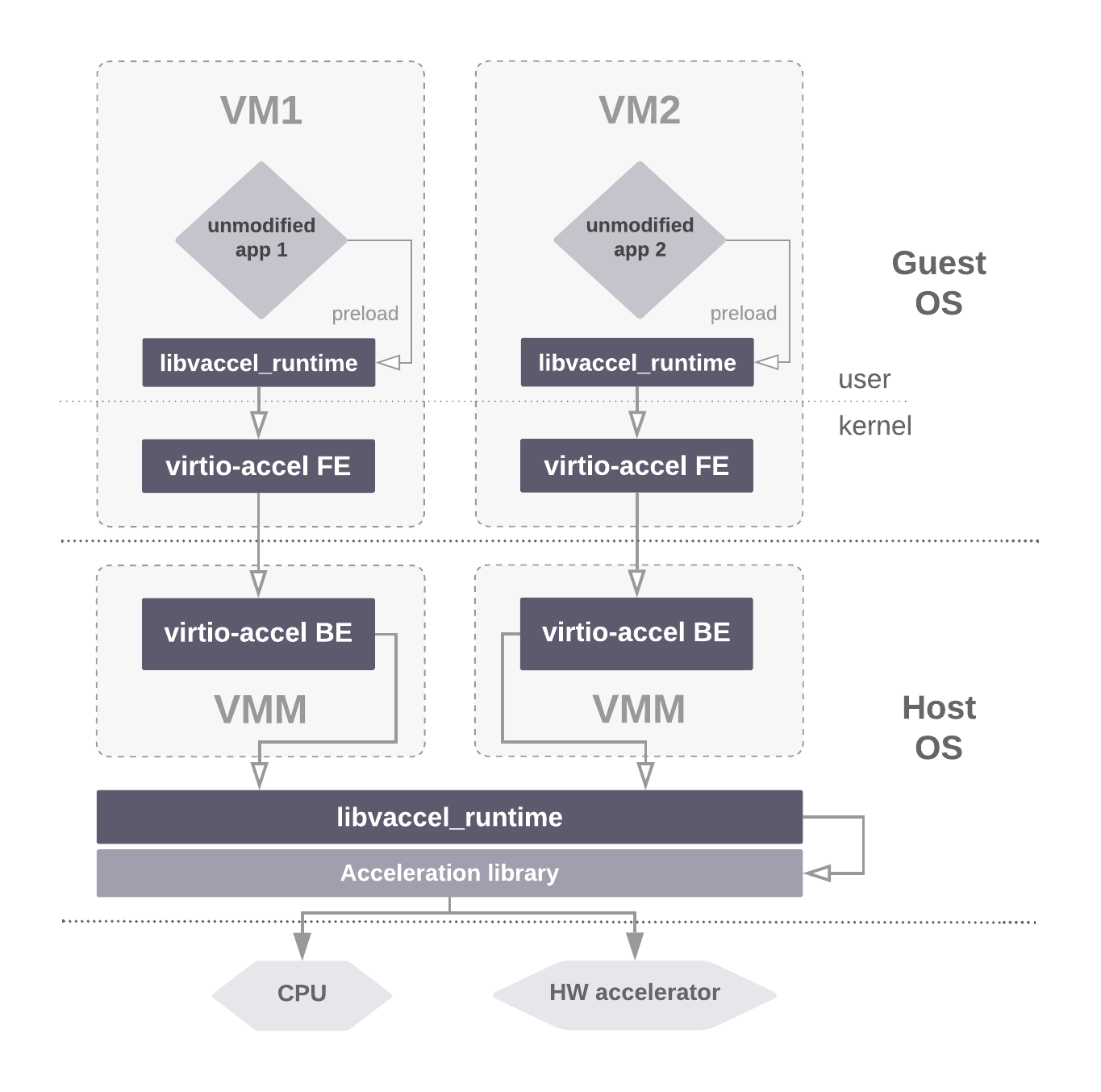
Figure 3: vAccel architecture overview
Frontend and Backend drivers implement the transport layer. We base our implementation on VirtIO, and follow the generic VirtIO spec, using a single queue for control and data exchange.
The runtime includes two components: a host library that handles offload requests, and a guest library that intercepts the actual offload-able user calls and creates those requests.
The basic API is given below:
1typedef uint8_t vaccel_op_t;
2
3/* Get available accelerate-able operations from the backend */
4int vaccel_get_operations(uint8_t *available_operations);
5
6/* Start a new session */
7vaccel_session_t *create_vaccel_session();
8
9/* Invoke an acceleration operation */
10int do_operation(vaccel_session_t *handle, vaccel_op_t operation, void *input, void *output);
11
12/* End a running session */
13int destory_vaccel_session(vaccel_session_t *handle);
To study the potential overhead of such an approach on a common function, we deploy a generic QEMU/KVM VM on an x86 host, using an FPGA card as the accelerator (SGEMM, implemented with OpenCL). We run the stencil on the host to obtain a baseline, and then we execute the same benchmark on the vAccel-enabled guest and capture the results.
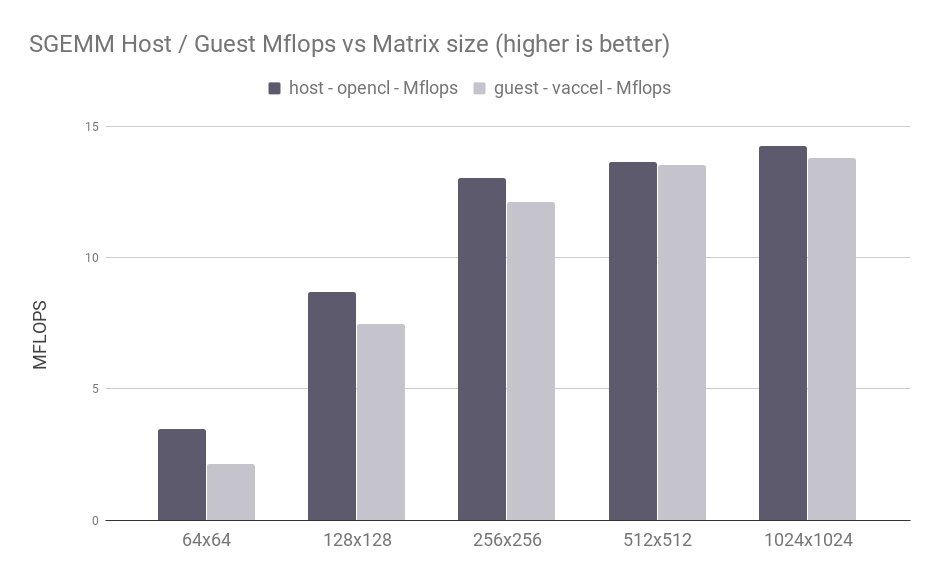
Figure 4: SGEMM Host / Guest results vs matrix size
Figure 4 presents the performance of SGEMM on a single core VM (light bars) against the respective run on the host (dark bars) for various matrix sizes. On the Y axis we plot the MFlops achieved by the SGEMM stencil, while on the X axis we lay the size of the matrices tested. For large matrix sizes (> 128x128), the overhead perceived by the user is minimal, ranging from 16% to even <3%.
Inference at the edge Link to heading
Let us now consider a more complicated scenario: image classification. From the user perspective it is a simple operation: (i) provide an image as input, (ii) define which model will be used to classify the image, (iii) wait for the result. However, the system internals are a bit more complicated: the image has to be preprocessed, fed to a pre-trained classification model, and mapped to a given set of labels. This abstraction is already provided by common frameworks such as Tensorflow, Caffe etc. However, these frameworks perform optimally with direct access to hardware accelerators. Figure 5 presents the path to the hardware accelerator from the VM’s userspace.
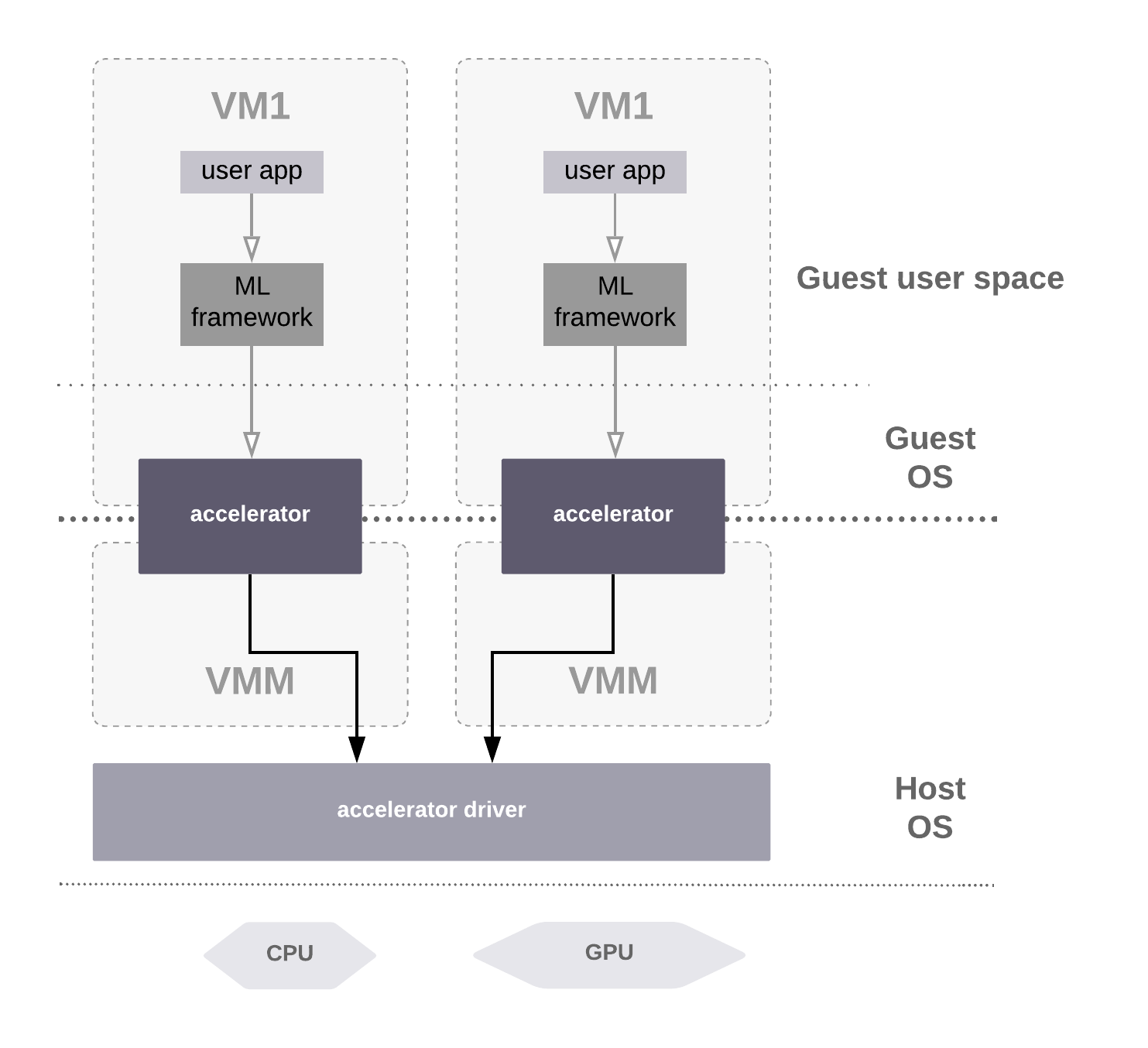
Figure 5: Inference use-case
We use vAccel to expose accelerated inference capabilities to a guest VM. Specifically, we expose one basic function, image classification. The guest simply issues a request with the image to be classified and the model to be used for inference. The backend forwards this request to vAccel-runtime, which, in turn, calls wrapper functions on top of the Tensorflow runtime to classify the image. The result is copied back to the guest synchronously. Figure 6 presents the vAccel-enabled path.
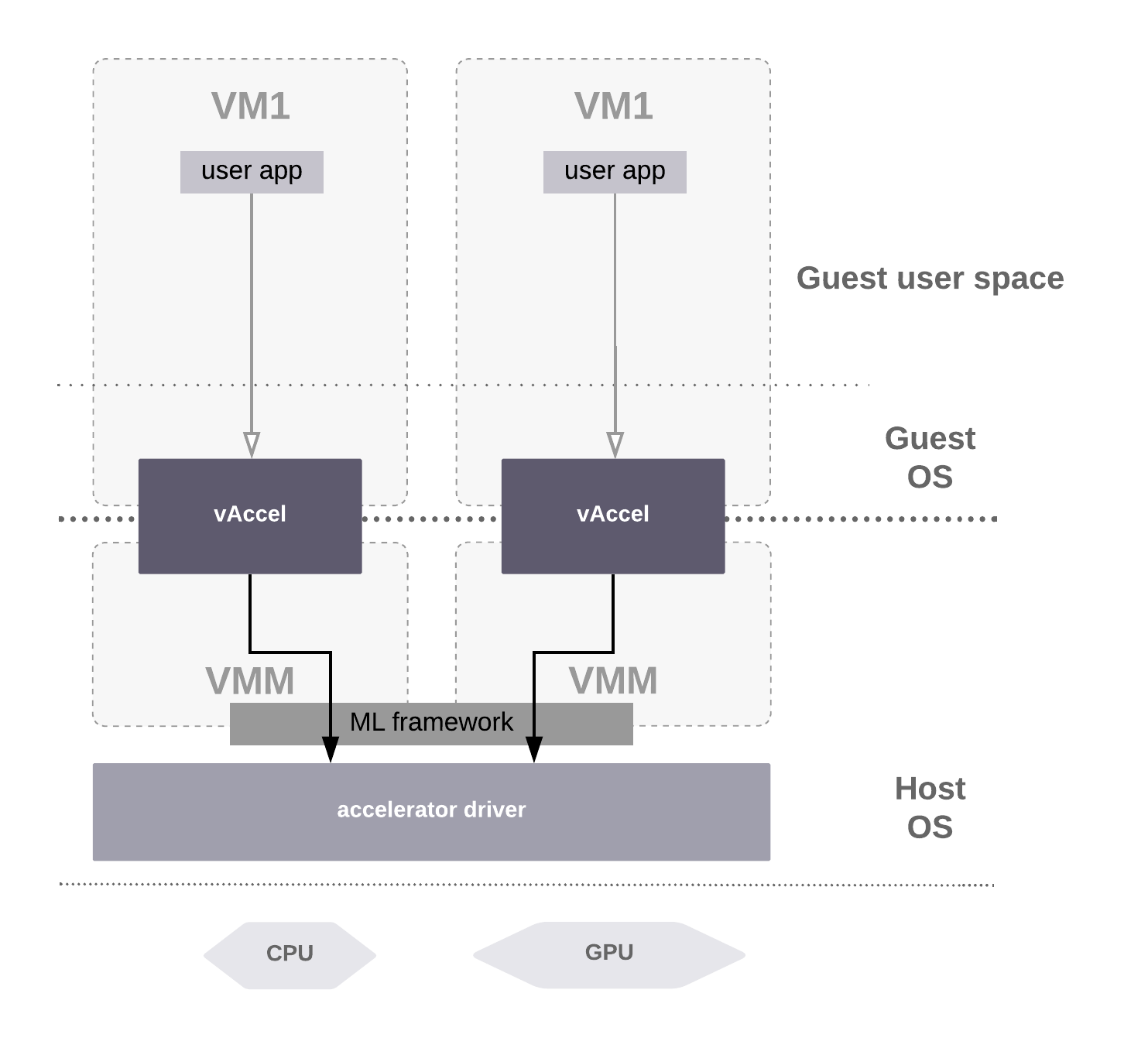
Figure 6: Inference use-case with vAccel
Figure 7 plots the total execution time of an image classification operation for various image sizes deployed on a generic QEMU/KVM VM on an NVIDIA Jetson Nano. Dark bars indicate the time required to complete the operation on the host, whereas light bars show the respective time spent on the guest. Clearly, the overhead is minimal: the average overhead across all cases is 1%.
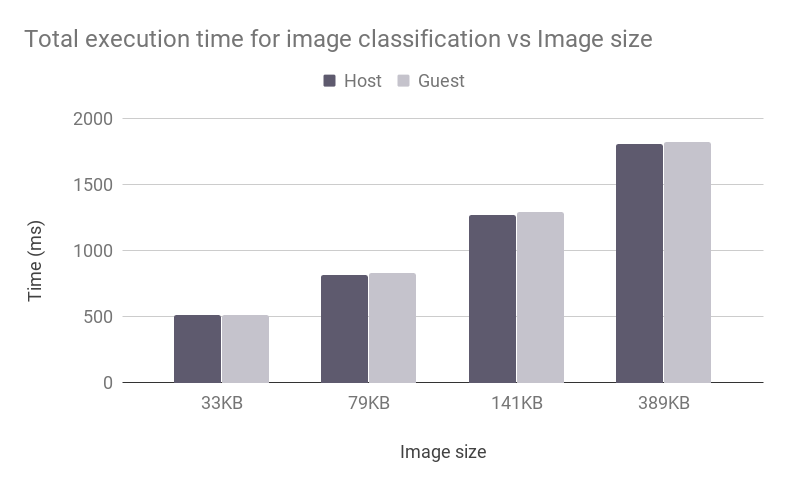
Figure 7: Image classification with vAccel
As execution moves to the Edge, following the Serverless paradigm, efficiency is key to provide low power consumption, while at the same time increase the quality and the diversity of services offered to the end user. Offloading computation to specialized units is one of the most important aspects to balance trade-offs related to resource utilization and energy-efficiency and to minimize request-response latency.
vAccel is being developed jointly by the Computing Systems Laboratory of the National Technical University of Athens and Nubificus LTD. vAccel is open-source and WiP; we plan to provide an RFC for the frontend driver to be upstreamed, as well as respective RFCs for the backends (QEMU, Firecracker etc.).