In our previous post we spoke about the potential solutions for deploying serverless offerings with hardware acceleration support. With the increasing adoption of the serverless and FaaS paradigms, providers will need to offer some form of hardware acceleration semantics.
For some time now, Amazon has identified this as a “compelling use case” for their AWS Firecracker hypervisor which powers the Amazon Lambda service. What is more, they identify traditional techniques for GPU support in VMs such as GPU passthrough comes with limitations and significantly increases the attack surface of the hypervisor.
As an alternative to passing through the accelerator device inside the guest, paravirtual interfaces can expose hardware acceleration capabilities inside the VM with minimal overhead and offering a simple user interface for offloading code to the host for acceleration.
In fact, such interfaces already exist. virtio-crypto is an example, where
the guest VM uses a simple crypto API while the actual computation is
offloaded, through the paravirtual driver, to the host.
We believe that the same paradigm can be applied to any kind of computation that can benefit from acceleration. Whether that is crypto operations, Machine Learning or linear algebra operators, the workflow from the point of view of the developer these days is the same; You will use a framework such as cryptodev, Jetson Inference or the BLAS library, to write your applications and you will not deal with the low-level complexities of the actual accelerator. Moreover, that workflow should not be different whether your application runs on baremetal or inside a VM.
In the rest of this post we present vAccel, an acceleration framework that enables portable and hardware agnostic acceleration for cloud and edge applications.
vAccel design Link to heading
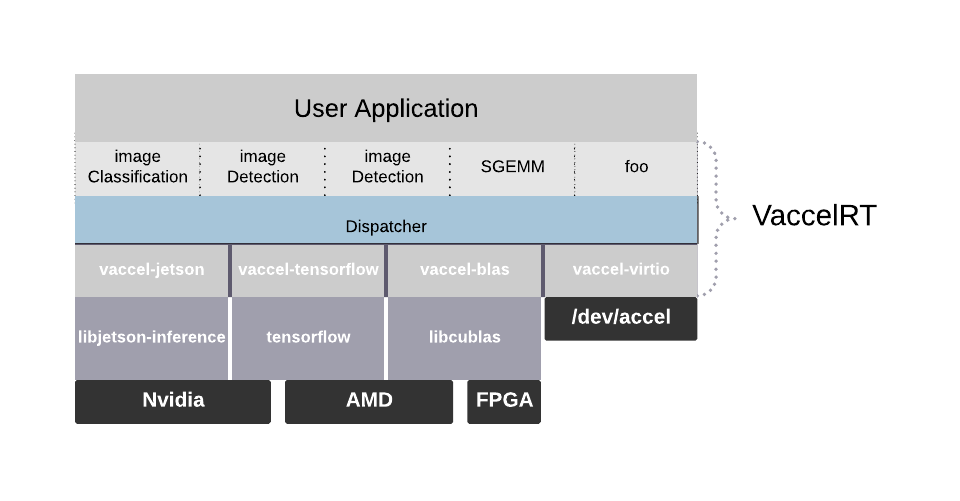
In simple terms, vAccel is an acceleration API. It offers support for a set of operators that commonly use hardware acceleration to increase performance, such as machine learning and linear algebra operators.
The API is implemented by VaccelRT a thin and efficient runtime system that links against the user application and is responsible for dispatching operations to the relevant hardware accelerators. The interaction with the hardware itself is mediated by plugins which implement the API for the specific hardware accelerator.
This design is driven by our requirements for high degree of portability, an application that consumes the vAccel API can run without modification or even re-compilation to any platform for which there is suitable back-end plugin.
In fact, this opens up the way to enable the vAccel API inside a VM guest. The missing bits are a virtio driver that implements the vAccel API and a backend plugin that speaks with the virtio device. Once you have this components in place, you can run your existing vAccel application inside a VM, just by using the virtio-plugin at runtime.
vAccel support in AWS Firecracker Link to heading
Once we implemented the frontend vAccel-virtio driver and virtio plugin for VaccelRT, we need a hypervisor to test this on. We already showed, in the previous post some initial vAccel results with QEMU as the target hypervisor. In this post, we will focus on AWS Firecracker.
AWS Firecracker has been designed having in mind really small boot times and small attack surface, which makes it a compelling choice for cloud and edge deployments. Moreover, it powers up Lambda, Amazon’s serverless platform, which we see as a paradigm for which vAccel’s hardware abstraction level is a perfect fit.
AWS Firecracker already implements virtio backend drivers for net, block and vsock. That was good news for us, we have all the required virtio machinery. All we had to do, was add a new device for vAccel and link the hypervisor with VaccelRT.
The last bit required us to create the necessary Rust bindings for calling C from AWS Firecracker which is written in Rust. This was actually a good exercise for us, since we plan to anyway provide bindings for the vAccel API in more high-level languages.
With all the components in place our stack looks like this:
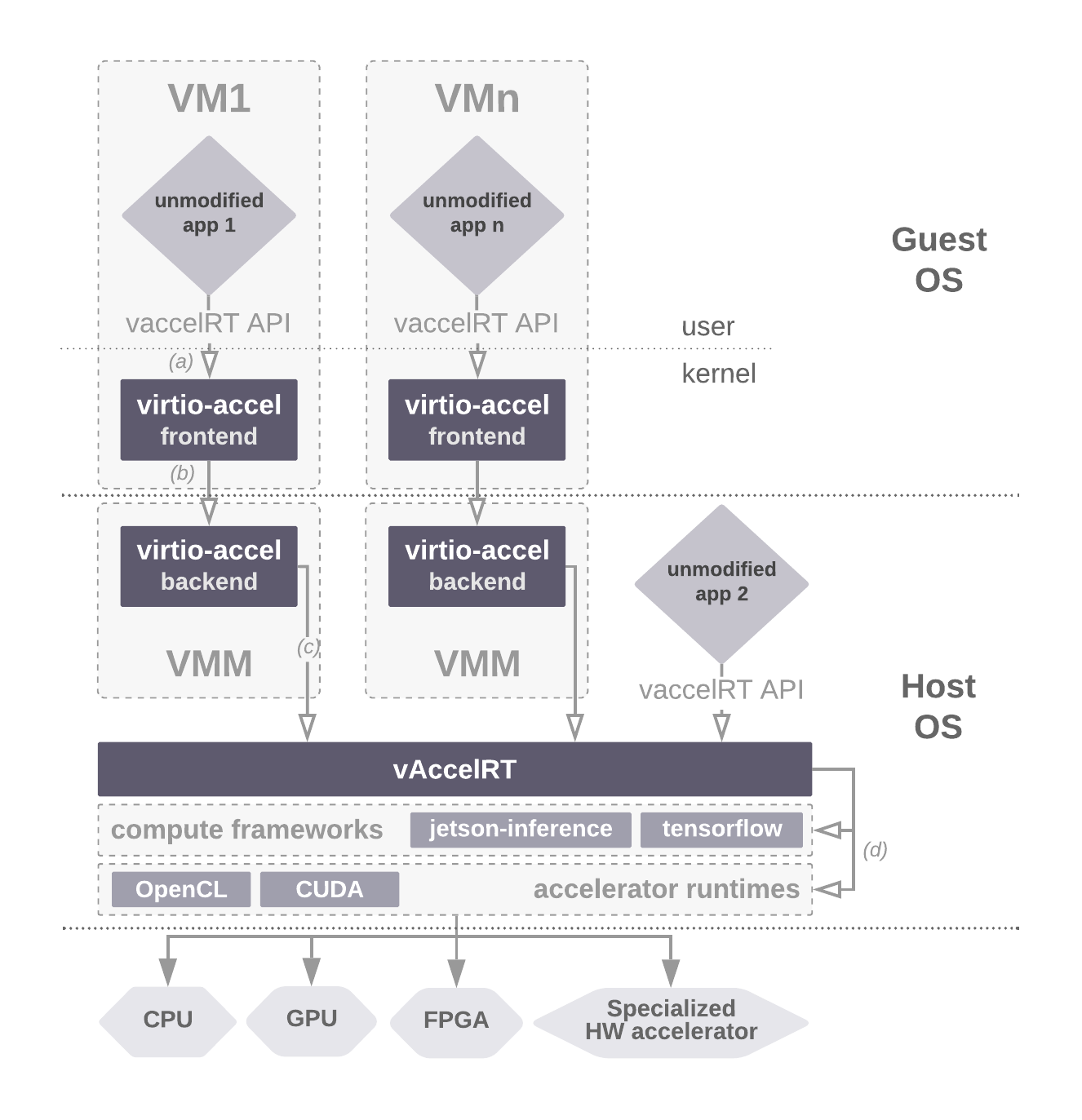
The user application is consumes the vAccel API and links against VaccelRT. Inside the VM
the application uses the vAccel-virtio backend plugin. When a vAccel function is called, the
plugin will offload the request to /dev/accel device which is the interface of the virtio
driver. Next, the virtio driver will forward the request to the vAccel-enabled AWS Firecracker
instance which will the host-residing VaccelRT. Finally, in the host side, VaccelRT will use
one of the available plugins, to execute the operation on the hardware accelerator.
But how does this perform?
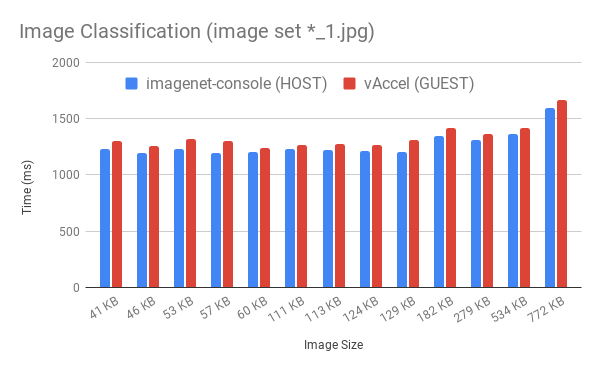
We first grabbed a copy of jetson-inference, a rich repo full of ML inference models and example applications based on TensorRT. We patched it to be able to run on an x86 GPU (we had an NVIDIA RTX 2060 SUPER handy), and we built the vAccelRT backend for an image classification operation. To compare vAccel on AWS firecracker we patched the example imagenet-console application to properly calculate the time of execution and to account for more than 1 iteration. The average execution time for image classification on two sets of Image files (set “*_0.jpg” and “*_1.jpg) are shown below:

The set above is sorted by the overhead percentage (GUEST vs HOST), while the set below, is sorted by Image size (in KB). One thing to note is that on all cases, the overhead of running an image classification operation in the guest compared to the host is less than 5%.
Putting it all together Link to heading
So, are you brave (or curious) enough to try it out yourself ? Full disclosure, vAccel is WiP, in terms of software development terms, the project should be considered in a pre-alpha phase. However, since we think the idea is useful, there might be someone willing to try it out. So here we go:
TL;DR The easy way to try vAccel on AWS Firecracker is to run the docker container bundled with all necessary libraries/tools etc. The only prerequisite is [Docker][https://github.com/NVIDIA/nvidia-container-runtime] & nvidia-container-runtime[https://github.com/NVIDIA/nvidia-container-runtime] installed.
To fire a VM up try running:
1docker run -e LD_LIBRARY_PATH=/usr/local/lib -e VACCEL_BACKENDS=/usr/local/lib/libvaccel-jetson.so --rm -it --gpus all --privileged nubificus/jetson-runtime
Now what the above command does is the following:
- sets up a couple of env vars to let the container know where to find the necessary libraries
- runs in a privileged mode so that /dev/kvm is available to the container instance (we need to boot a VM in there ;))
- provides access to the GPU from the container.
The entrypoint for the above container image (nubificus/jetson-runtime) simply starts a firecracker VM with a pre-built kernel & rootfs.img, available here. This repository contains the dockerfile from which these binaries have been produced. You can download ready-made binaries from the releases page.
If (for any reason) you want to try out jetson-inference, without the AWS Firecracker VM boot, then just run the container with /bin/bash as an entrypoint, using the following command:
1docker run --network=host --rm -it --gpus all --privileged -v nubificus/jetson-runtime /bin/bash
Host Link to heading
The current available version of vAccelRT supports the jetson-inference plugin. Adding a new plugin is as easy as linking with vAccelRT and writing the glue code in the plugin directory – more information should be available in the coming weeks!
To use this plugin, the Host machine should have an NVIDIA GPU (supporting CUDA), the relevant drivers installed, as well as jetson-inference installed.
The next step is to build & install vAccelRT, the glue that ties everything together. You can build it from source, or just install the binaries available from the releases page. Make sure you specify LD_LIBRARY_PATH to the folder where libvaccel.so is located, as well as to choose the necessary backend by setting VACCEL_BACKENDS to libvaccel-jetson.so.
1export LD_LIBRARY_PATH=/usr/local/lib
2export VACCEL_BACKENDS=/usr/local/lib/libvaccel-jetson.so
VM Link to heading
To run a vAccel-enabled VM, we need four basic components:
- the AWS firecracker VMM (with the vAccel backend patch) github releases
- a firecracker guest Linux kernel supporting modules + the virtio-accel module github releases
- the vAccel runtime system (vAccelRT) for the Host and the guest github releases
To facilitate the process of packing all these software components, we include links to binaries built from the respective github repositories.
Grab, or build vmlinux & the rootfs.img from the links above, and use a template config for firecracker like the following:
1{
2 "boot-source": {
3 "kernel_image_path": "vmlinux",
4 "boot_args": "console=ttyS0 reboot=k panic=1 pci=off loglevel=0 root=/dev/vda quiet"
5 },
6 "drives": [
7 {
8 "drive_id": "rootfs",
9 "path_on_host": "rootfs.img",
10 "is_root_device": true,
11 "is_read_only": false
12 }
13 ],
14 "network-interfaces": [
15 {
16 "iface_id": "eth0",
17 "guest_mac": "AA:FC:00:00:00:01",
18 "host_dev_name": "tap"
19 }
20 ],
21 "crypto": {
22 "crypto_dev_id": "vaccel0",
23 "host_crypto_dev": "/dev/vaccel0"
24 },
25 "machine-config": {
26 "vcpu_count": 1,
27 "mem_size_mib": 1024,
28 "ht_enabled": false
29 }
30}
Make sure vmlinux, rootfs.img are in the same directory as the invocation of the firecracker command. Also, ensure that you have set LD_LIBRARY_PATH and VACCEL_BACKENDS correctly, and that you’ve downloaded the ML networks needed for inference. This step can be done using this script. Just get this script and run:
1./download-models.sh NO
and the models will be placed by default at ../data/networks. Change the path in the script if you need to. For the AWS Firecracker backend to work, we need the models in the same directory as the invocation of the firecracker binary, in a folder called networks.
Now, we’re ready to fire up our VM:
1firecracker --api-sock /tmp/fc.sock --config-file config_vaccel.json --seccomp-level 0
aaand we get the following:
12020-12-04T14:39:02.363414625 [anonymous-instance:WARN:src/devices/src/legacy/i8042.rs:126] Failed to trigger i8042 kbd interrupt (disabled by guest OS)
22020-12-04T14:39:02.369542154 [anonymous-instance:WARN:src/devices/src/legacy/i8042.rs:126] Failed to trigger i8042 kbd interrupt (disabled by guest OS)
3SELinux: Could not open policy file <= /etc/selinux/targeted/policy/policy.32: No such file or directory
4[ 0.970330] systemd[1]: Failed to find module 'autofs4'
5[UNSUPP] Starting of Arbitrary Exec…Automount Point not supported.
6
7Ubuntu 20.04.1 LTS vaccel-guest.nubificus.co.uk ttyS0
8
9vaccel-guest login:
Some harmless messages and a login prompt! Try root for username (no password).
1vaccel-guest login: root
2Welcome to Ubuntu 20.04.1 LTS (GNU/Linux 4.20.0 x86_64)
3
4 * Documentation: https://help.ubuntu.com
5 * Management: https://landscape.canonical.com
6 * Support: https://ubuntu.com/advantage
7
8This system has been minimized by removing packages and content that are
9not required on a system that users do not log into.
10
11To restore this content, you can run the 'unminimize' command.
12
13The programs included with the Ubuntu system are free software;
14the exact distribution terms for each program are described in the
15individual files in /usr/share/doc/*/copyright.
16
17Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
18applicable law.
19
20root@vaccel-guest:~#
Bear in mind, the rootfs.img is based on docker hub’s ubuntu latest.
Now lets do some image classification! Try running the following:
1root@vaccel-guest:~# ./classify images/airplane_1.jpg 1
2Initialized session with id: 1
3Image size: 115835B
4classification tags: 21.973% warplane, military plane
The first time the execution might take longer, but any consecutive run will be significantly faster. This is because the acceleration backend (jetson-inference) needs to examine the hardware available, generate and load the necessary components for the model to run correctly.
That’s it! you just ran an image classification example for a JPG image, in an AWS Firecracker VM, talking vAccelRT, which, in turn, forwards this request to AWS Firecracker vAccel backend, calling vAccelRT, jetson-inference, talking to the GPU and voila!
Future steps Link to heading
Argh! you made it this far? :D If you enjoyed playing with hardware acceleration & Firecracker stay tuned to enjoy some more of this on aarch64 devices (yeap, the NVIDIA Jetson Nano!). Last but not least, we are in the process of integrating vAccel-enabled AWS Firecracker instances to k8s and k3s to facilitate deployment and scaling.
Give us a shout at team@cloudkernels.net if you liked it, or visit the vAccel website and drop us a note at vaccel@nubificus.co.uk for more info!